Wine Review Learning and Recommendation
Life is data. Here the machine learning is going to tell the wine’s story by doing testers’ job.
I used two popular ML mothods, Random Forest and Boosting to build the regression model on the wine score with the data from Winemag.
By recommanding the Pinot Noir from outstanding winery, we can also see testers’ preference or inclination.
Here is the Report generated by R .rmd file
Skin Cancer Diagnosis Learning
Skin cancer, as the abnormal growth of skin cell, is one of the most common cancer in the US. The curing effect to it is based on detection in the early stage.
This machine learning project is to verify the detection methods according to skin cancer lesion area with different learning models.
The first part of the project is to fit three classifiers on the diagnosis image pixel, and analyze the prediction result after PCA transform. Below are the learning mothods:
- K-Nearest-Neighbors
- Support Vector Machine
- Random Forest
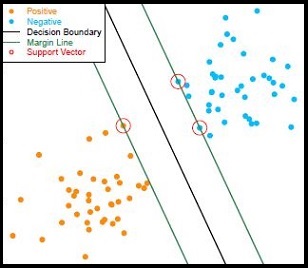
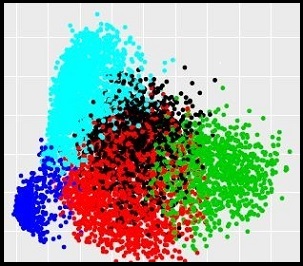
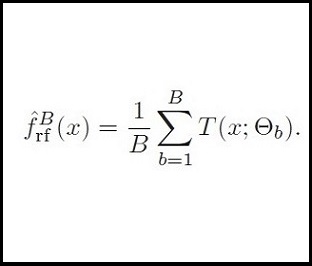
The second part is to extract visible features from the images after effective image processing (applying knn in skin area recognition), then fit classifiers based on our new features, which will be more interpretable to skin cancer diagnosis. Here is the learning methods:
- Logistic Regression
- Decision Tree

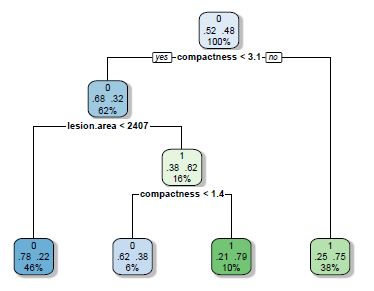
Here is the Report generated by R. Note: Some images may be unpleasant. .rmd file
Normal detection rate from dermatologist is 54%
Models on the 1st section sucessfully detect ~75% skin cancer.
Models on the 2nd section sucessfully detect ~70% skin cancer.
Bag-of-Word (BOW) Processing and Doc Search Engine Simulation
- Prepocessing to thousands of yelp reviews, identify the stop words and determine the minimal word occurance for Bag-of-word vector construction.
- Search certain words with inclination to find the target reviews.
- Build a logistic classifier based on the training set from all review’s BOW vectors/labels
- The final accuracy on the test set is 97%
- Use ROC to verify the classifier in different threshold
Stop Word:
SW = ['the', 'an', 'a', 'and', 'or', 'from', 'to', 'in', 'out', 'about', 'am', 'are', 'is', 'was', 'be', 'been',
'I', 'you', 'he', 'she', 'we', 'they', 'this', 'that', 'these', 'those', 'my', 'your', 'his', 'her', 'their', 'our',
'on', 'with', 'without', 'has', 'have', 'had', 'me', 'him', 'her', 'us', 'them', 'it', 'for', 'of', 'at', 'as', 'so',
'because', 'then', 'but', 'although', 'though', 'if', 'already', 'yet', 'here', 'there', 'were', 'would', 'could']
Use sklearn to get the BOW vectors:
...
vectorizer_optimized = CountVectorizer(stop_words = SW, max_df = 1000, min_df = 2) ## Instantiate an object,
Vec_optimized = vectorizer_optimized.fit_transform(list(docs['X']))
X_optimized = Vec_optimized.toarray()
Convolutional Neural Net (CNN) Image Classification with PyTorch

-
This job is to tell what’s displayed on the popular ML image dataset(CIFAR10). The images are presenting 10 different classes: airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks.
-
Use PyTorch to construct the two-layer fully-connected (single hidden layer) model, optimization function and track the loss function. Final Accuracy: %39.2
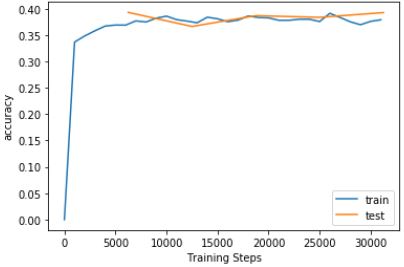
- Construct 2-layer CNN with 3x3 filters, activation, pooling, stride, padding and generate classification output from linear function. Final Accuracy: 53.5%
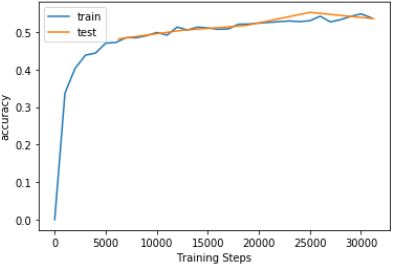
- Construct ResNet with 3x3 filters, activation, pooling, stride, padding and generate classification output from linear function. The performance is enhanced by decreasing learning rate as epoch increase. Shortcut input is added to the prevent gradient vanishing in learning. Final Accuracy: 93.2%
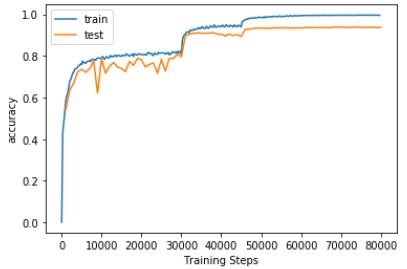
- Apply GPU in (Google colab)[https://colab.research.google.com/notebooks/welcome.ipynb] to train the convolutional Neural Net with input of all tensors.
Activities of Daily Living (ADL) Classification with Vector Quantization

This project is trying to detect 14 ADLs from the sensor single. Volunteer wear the sensor on their hand, foot, leg, neck etc. and their body movement will be captured by the sensors. Theorectically similar activities, e.g. Brush Teech, will generate similar signal. However, the singal is recorded with random time window so we don’t know which section of the signal is for the specific activities. :(
| Index | ADL |
|---|---|
| 1 | Brush Teeth |
| 2 | Climb Stairs |
| 3 | Comb Hair |
| 4 | Descend Stairs |
| 5 | Drink Glass of Water |
| 6 | Eat Meat |
| 7 | Eat Soup |
| 8 | Get Up from Bed |
| 9 | Lie Down |
| 10 | Pour Water |
| 11 | Sit Down Chair |
| 12 | Stand Up Chair |
| 13 | Use Telephone |
| 14 | Walk |
So, I used vector quantization, slice the whole signal into different length of piece with different overlap setting. The slice are clustered into specific cluster and there will be pattern of the slice in these clustering. The classifier is trained based on the pattern. The training process apply cross-validation.
By adjusting the slice length, overlap, clustering quantity, the classifier can learn the vector slice pattern and improve the precision.
This method is powerful when we want to monitor any signal or signal-related activities.
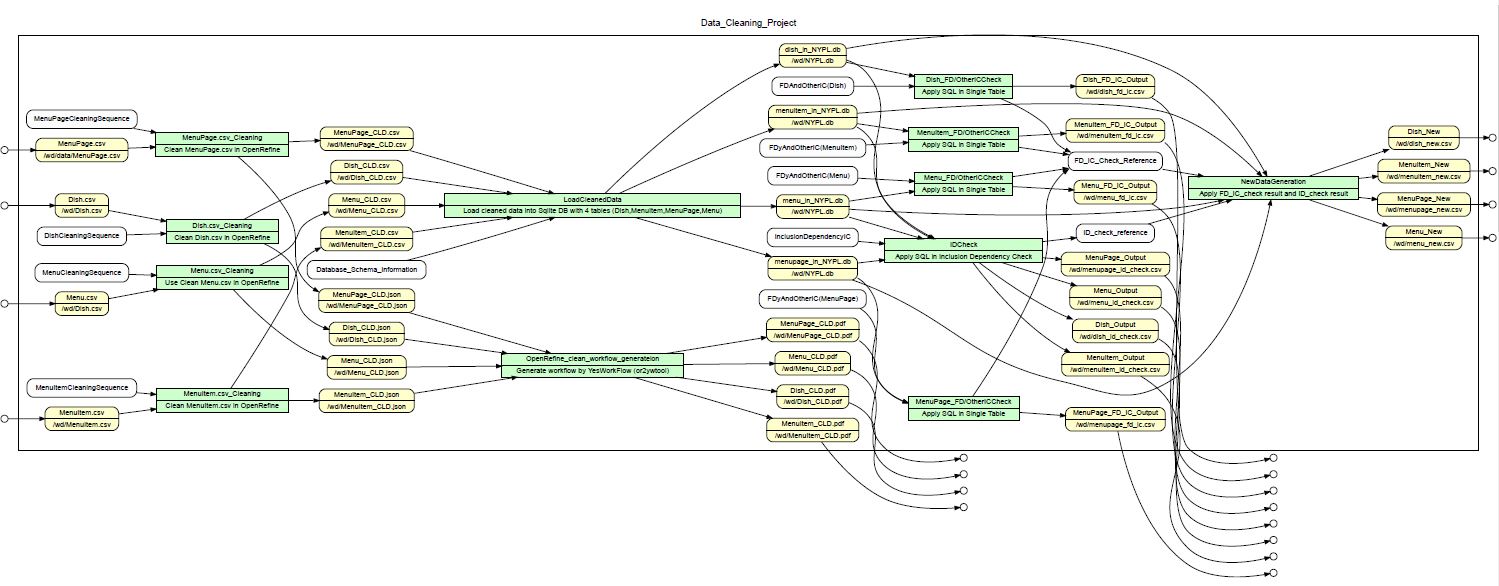
Practical Data Cleaning
This project is real data cleaning process.
Our data is based on one of famous New York Public Library project which track the dish and menu evolution in NYC since 1900.
Cleaning process focus on missing data, informal input or inconsistent format.
The post-processed data are used to input SQLite for integrity constraint (IC) check. This processed is coded by python.
Very neat scientific workflow is generated to describe the cleaning roadmap in YesWorkflow program.